

Onderzoekers van Microsoft hebben een indrukwekkend nieuw text-to-speech-model gepresenteerd. Vall-E kan na enkele seconden naar een stem te luisteren dat stemgeluid al nabootsen.
Waren digitale voorleesstemmen een tijdje geleden nog niet om aan te horen, dankzij text-to-speech-software (TTS) klinken ze steeds natuurlijker. Alleen was emotie in een stem leggen nog iets te hoog gegrepen voor het systeem. Daar heeft Microsoft nu verandering in gebracht met VALL-E. Dit text-to-speechmodel kan volgens de techgigant na slechts 3 seconden je stem gehoord te hebben complete zinnen genereren die barsten van de emotie en intonatie.
Lees ook:
Hoe werkt text to speech (TTS)?
Een TTS-systeem gebruikt een zogenoemd deep neural network, dat in staat is nieuwe dingen te leren uit grote hoeveelheden data. Wanneer je bijvoorbeeld bergen tekst en audio aan zo’n neuraal netwerk voert, zal het relaties tussen die twee vaststellen. Met andere woorden: als het genoeg input krijgt, weet het na verloop van tijd welke klanken bij welke geschreven woorden horen. Aan de hand daarvan voorspelt het hoe de woorden die het ‘leest’ moeten worden uitgesproken.
Naast het model dat relaties legt tussen audio en geschreven tekst bevat een TTS-systeem ook een model dat een digitale weergave van een stem maakt. Zo’n digitale weergave heet een vector en ziet eruit als een audiogolf; een horizontale lijn met verticale lijnen erbovenop. Die verticale lijnen tonen de eigenschappen van de stem, zoals de spreeksnelheid en de intonatie. Zo kan een hoge stem worden weergegeven als een hoge verticale lijn, terwijl diezelfde lijn bij een lage stem korter kan zijn. Voor mensen is die audiogolf niet te lezen, maar een computer kan er wel mee overweg.
Om geschreven tekst om te zetten in audio heeft een TTS-systeem beide modellen nodig. Wanneer een tekst wordt ingevoerd, zet het TTS-systeem die met behulp van het eerste model om in fonemen: kleine stukjes geluid die samen de basis van de spraak vormen. De software schrijft al die fonemen uit en zet de letters om in cijfers, die het neurale netwerk inleest. Dat probeert vervolgens te voorspellen hoe de stem die het al in kaart heeft gebracht die groepen fonemen zou uitspreken. Een zogenoemde vocoder gebruikt de vector om te kijken hoe de stem is opgebouwd en om te bepalen hoe de klanken die de digitale stem uitspreekt moeten klinken. En dat doet de software allemaal in een fractie van een seconde.
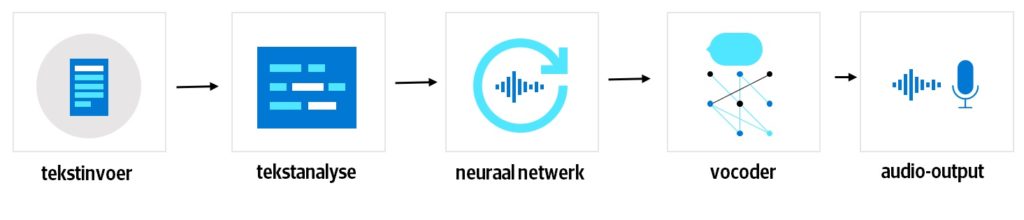
horen. Aan de hand daarvan voorspelt het model hoe het denkt dat de woorden die het leest moeten worden uitgesproken. © Microsoft
VALL-E
Microsofts VALL-E is getraind met 60.000 uur aan Engelstalige spraakopnames. Om het systeem te testen, gebruikten de onderzoekers stemsamples van studenten van de Cornell University in New York. De resultaten verschilden. Sommige spraakopnames wisten de essentie van de stem vast te leggen en nieuwe zinnen te maken die natuurlijk klonken. Maar in andere gevallen was duidelijk te horen dat de opnames door software waren gegenereerd. VALL-E legde bijvoorbeeld de klemtoon op vreemde plaatsen in de zin.
Verder heeft de software nog wat moeite met enkele emoties: boze, slaperige, en verontwaardigde stemmen lijken de boel op hol te brengen. De resulterende opname klinkt dan erg vervormd. Ook kan het voorkomen dat VALL-E bepaalde woorden onduidelijk uitspreekt, overslag of juist dubbel noemt in de output.
Surprised there isn't more chatter around VALL-E
— Steven Tey (@steventey) January 9, 2023
This new model by @Microsoft can generate speech in any voice after only hearing a 3s sample of that voice ?
Demo → https://t.co/GgFO6kWKha pic.twitter.com/JY88vf4lYc
De inhoud op deze pagina wordt momenteel geblokkeerd om jouw cookie-keuzes te respecteren. Klik hier om jouw cookie-voorkeuren aan te passen en de inhoud te bekijken.
Je kan jouw keuzes op elk moment wijzigen door onderaan de site op "Cookie-instellingen" te klikken."
Je kan jouw keuzes op elk moment wijzigen door onderaan de site op "Cookie-instellingen" te klikken."
Toch presteert VALL-E veel beter dan de huidige TTS-modellen. Zo is het bijzonder goed in het nabootsen van de geluidsomgeving van de originele sample. Als een stem namelijk klinkt alsof hij via een telefoon is opgenomen, dan klinkt de geïmiteerde opname ook zo. Daarnaast is VALL-E vrij goed met accenten, hoewel dat tot nu toe alleen Amerikaanse, Britse en een paar Europese zijn.
Knap staaltje werk, maar er schuilt ook een gevaar in. Net als van deepfakes is er van text-to-speech-modellen makkelijk misbruik te maken, geven de onderzoekers ook toe in hun paper. Wat dat betreft is het fijn dat VALL-E nog niet vrij beschikbaar is. En wordt de software wel openbaar gemaakt, dan kunnen programmeurs een model ontwikkelen dat onderscheid kan maken tussen echte en kunstmatige stemmen, verzekert Microsoft.
Bronnen: arXiv.org, New Atlas, Tweakers, KIJK 3/2022
Beeld: 123RF