

Met slechts een paar seconden audio van iemands stem kan voice cloning-software die persoon alles laten zeggen wat je wil. En een groot deel van de Nederlanders tuint erin. Maar hoe werkt het?
De overgrote meerderheid van de Nederlanders ontvangt wel eens misleidende tekstberichten en e-mails van online criminelen die zich voordoen als een bekende of een betrouwbare organisatie. Met een door AI gekloonde stem kunnen online criminelen nu ook écht zo klinken. Uit recent onderzoek van de Rijksoverheid blijkt dat meer dan de helft van de Nederlanders geen verschil hoort tussen een echte en gekloonde stem van bekende.
In 2020 schreven we al over het fenomeen voice cloning. Journalist Nick Kivits onderzocht toen voor KIJK hoe deze techniek werkt, en liet ook zijn eigen stem klonen. Hieronder vind je zijn verhaal.
Lees ook:
Fraudeurs
Photoshop voor audio: zo omschrijft onderzoeker Zeyu Jin de door hem bedachte software VoCo, die hij in november 2016 voor het eerst aan de wereld laat zien. Op een conferentie van zijn werkgever Adobe laat Jin de stem van comedian Keegan-Michael Key horen, die zegt: “I jumped on the bed and I kissed my dogs and my wife. In that order.” Een paar vlugge toetsaanslagen later schalt de stem van Key opnieuw door de zaal: “And I kissed Jordan three times.” Woorden die de comedian nooit gezegd heeft. Hem digitaal in de mond gelegd door Jin.
“VoCo stelt je in staat iemands gesproken woord te veranderen met behulp van een tekstverwerker”, legt Jin op de conferentie uit. Zijn zelflerende ‘deep learning’-software analyseert de stem van de spreker en interpreteert aan de hand van die analyse hoe die persoon andere woorden uitspreekt. Door de zinnen die je de persoon wil horen zeggen in te typen in een tekstverwerker genereert VoCo de audio die daarbij hoort. VoCo heeft aan twintig minuten bronmateriaal genoeg om de stem van een spreker te klonen.
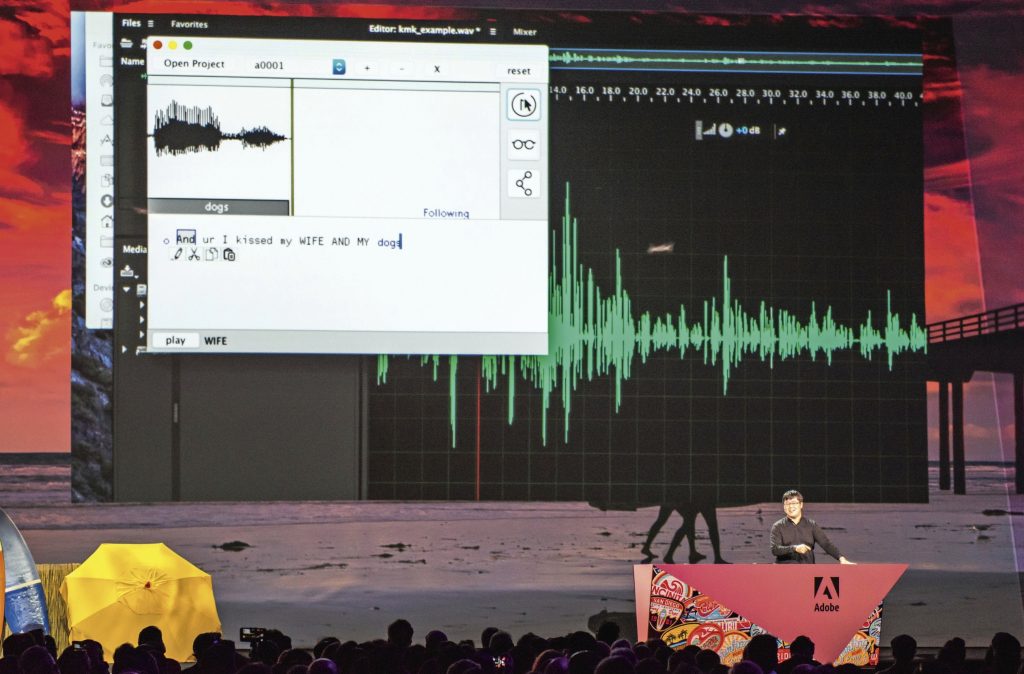
Drieënhalf jaar na Jins presentatie is VoCo nog altijd niet te koop. Maar andere softwarebedrijven hebben in de tussentijd niet stilgestaan. Inmiddels zijn er een stuk of vijf die text-to-speech-synthesis (TTS, spraak-naar-tekst-synthese) onder de knie hebben. Zo bracht het Amerikaans iSpeech in 2013 al grappig bedoelde apps uit waarmee je de voormalige presidenten George W. Bush en Barack Obama woorden in de mond kunt leggen. En het Canadese Lyrebird bouwde in 2017 net als Adobe een systeem voor voice cloning.
Vandaag de dag kost het klonen van een stem niet meer dan een paar seconden en fantaseren bedrijven over de toepasmogelijkheden. Maar er zijn ook zorgen: namelijk over het scala aan mogelijkheden die de techniek biedt aan fraudeurs.
Secondewerk
Dat voice cloning inmiddels razendsnel gaat, bewijst Baidu. De Chinese softwaregigant slaagde er in 2018 in stemmen na te bootsen met niet meer dan 3,7 seconden aan bronmateriaal. Nog sneller is de Real-Time Voice Cloning Toolbox, vorig jaar ogenschijnlijk uit het niets online gezet door de Belgische machine learning-ingenieur Corentin Jemine. De toolbox heeft aan twee seconden audio genoeg. Jemine bouwde hem in acht maanden tijd als afstudeerproject voor zijn master Data Science/Machine Learning.
“De theorie erachter bestond al”, vertelt Jemine in zijn appartement in het Belgische Namen. “Google heeft uitgebreid onderzoek gedaan naar TTS-systemen, maar bracht zelf nooit dergelijke software uit. Voor mijn afstuderen wilde ik iets bouwen met een wow-factor. Dus besloot ik het onderzoek van Google in de praktijk te brengen en een deep learning-model te bouwen dat zelf leert hoe stemmen in elkaar zitten en ze ook na kan maken.”
Sinds juni 2020 werkt Jemine vanuit huis voor het Canadese softwarebedrijf Resemble AI verder aan een vernieuwde versie van zijn toolbox. Die bestaat eigenlijk uit twee verschillende zelflerende neurale netwerken: de voice encoderen de synthesizer. “De voice encoder maakt een digitale weergave van een stem”, legt de machine learning-ingenieur uit. “Die weergave – een zogenoemde vector – bevat 256 waardes die karakteristiek zijn voor die stem. Voor een mens is zo’n vector niet te lezen. Maar een computer kan er wel mee overweg.”

Om de voice encoder te leren hoe hij de verschillende stemmen kan onderscheiden, moest Jemine hem eerst trainen. Dat deed hij met een database van 15.000 stemmen die de machine-learning ingenieur uit YouTube-video’s viste. De voice encoder luisterde naar al die stemmen en bracht de verschillen in kaart. Hoe meer stemmen het model beluistert, hoe beter hij wordt in het onderscheiden van die verschillen.
Ook het tweede neurale netwerk dat Jemine bouwde, de synthesizer, heeft hij moeten trainen. “Ik heb de synthesizer audiobestanden van 2000 verschillende stemmen gevoerd, met per fragment een transcriptie van wat er wordt gezegd”, legt Jemine uit. Met die input kon het neurale netwerk de manieren waarop letters kunnen klinken in kaart brengen. Zodat hij die klank later kan reproduceren.
DIY voice cloning
De twee neurale netwerken komen in het model van Resemble AI samen. Als je audio van een nieuwe stem inlaadt, pluist de voice encoder uit hoe de stem in elkaar steekt. De vector die dat oplevert wordt ingevoerd in de synthesizer. Typ je vervolgens tekst in, dan genereert de synthesizer de klanken die bij de geschreven tekst horen met de eigenschappen van de stem die de voice encoder heeft geanalyseerd. Het model kan met verschillende talen overweg, maar werkt vooralsnog het best in het Engels, omdat dat de taal is waar het neurale netwerk het uitvoerigst mee is getraind.
Als proef op de som vraagt Jemine me mijn eigen stem op te nemen, terwijl ik zinnen oplees als ‘It’s easy to tell the dept of a well’ en ‘An ox came down to the pool to drink water’. Hoewel twee seconden audio genoeg is om mijn stem te klonen, moet ik vijftig zinnen oplezen. Want hoe meer input het model heeft, hoe beter het resultaat. Jemine: “Met dertig helder gesproken zinnen kom ik al een heel eind.”
Het opnemen van de zinnen gaat via de website van Resemble AI (resemble.ai) en staat voor iedereen open. Enkele minuten na het inspreken is de digitale kloon van mijn stem klaar. In dezelfde web-omgeving kan ik direct enkele zinnen invoeren, die mijn kloon voor me oplepelt. En dat doet hij direct al redelijk vlot. Het resultaat is indrukwekkend, maar klinkt nog overduidelijk als een computer: een beetje blikkerig en krakend.
“In de geautomatiseerde demo vergelijkt de synthesizer je stem met alle stemmen die hij kent”, legt Jemine uit. “Voor het beste resultaat moet ik het een beetje finetunen en hem je stem alleen laten vergelijken met stemmen die op de jouwe lijken.” Jemine regelt dat in een paar minuten, waarna een bijna perfecte reproductie van mijn stem plots de Engelse tongbreker Peter Piper picked a pack of pickled peppers, how many pickled peppers did Peter Piper pick voordraagt. Zonder te stotteren.
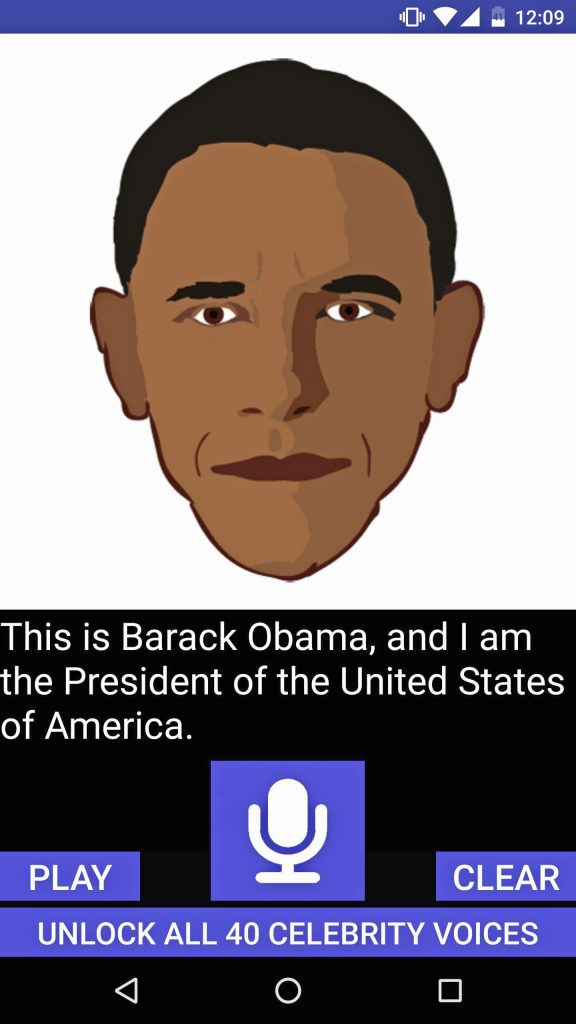
iSpeech Obama kun je de voor-
malige Amerikaanse president
woorden in de mond leggen.
De gratis app werd gemaakt voor iOS, Android en BlackBerry. © iSpeech
Mijn kloon is niet perfect, waarschuwt Jemine. Vooral met interpunctie gaat hij nogal eens de mist in: hij stopt vaak niet aan het eind van een zin, maar dendert gewoon door. Dat komt doordat ik tijdens het inspreken van mijn bronmateriaal zelf ook punten en komma’s heb genegeerd. Al weet de machine learning-engineer ook dat een paar dagen later alsnog goed weg te poetsen met een nieuwe versie van het model. Bij sprekers die duidelijker articuleren en minder mompelen dan ik is de kloon nauwelijks van echt te onderscheiden. Zoals bij Lucy, een virtueel personage van Fable Studio. Op een beurs over ‘virtuele wezens’ in Los Angeles gebruikte dit bedrijf het model van Resemble AI om Lucy’s stem automatisch te genereren.
Persoonlijke reclame
Virtuele wezens een stem geven zonder een acteur miljoenen zinnen in te laten spreken is maar één van de mogelijke toepassingen van digitaal gekloonde stemmen. Game-makers kunnen met TTS-modellen stemmen genereren en gebruiken om bewegingen van monden te animeren. En de reclamewereld kan gekloonde stemmen inzetten om gesproken advertenties te personaliseren, zodat advertenties die je online tegenkomt je bij je naam kunnen aanspreken. Om maar wat voorbeelden te noemen.
De indrukwekkende resultaten van voice cloning roepen echter ook terechte angst op voor misbruik ervan. Kwaadwillenden kunnen de modellen gebruiken om mensen woorden in de mond te leggen, om zo desinformatie te verspreiden of mensen op te lichten. Adobe kondigde daarom in 2016 al aan systemen te ontwikkelen die nepstemmen moeten herkennen. Ook Resemble AI werkt daaraan, zegt Jemine. “We hebben een neuraal netwerk gebouwd dat beoordeelt hoe goed een gekloonde stem lijkt op de originele stem. Het model vergelijkt de twee en geeft de gekloonde stem cijfers op gebieden als snelheid en of de uitspraak klopt bij de geschreven tekst.”
Maar dat model is ook te gebruiken om nepstemmen te ontmaskeren. Jemine laat de resultaten zien van een test waarbij het model twaalf audioclips van de Amerikaanse president Donald Trump op echtheid moest beoordelen. Van de zes gefakete fragmenten herkende het model er vijf. Jemine: “Dat is de ironie van machine learning: het model dat het beste resultaat oplevert is vaak ook het best in het opsporen van fakes die met soortgelijke modellen gemaakt zijn.”
Toch zullen we in de toekomst nog meer op onze hoede moeten zijn voor nepinformatie en misleiding. Even bij je kennis checken of hij daadwerkelijk wil dat je met spoed tweeduizend euro naar hem overmaakt, zoals zijn voicemailbericht deed geloven, is dan ook zeker geen verkeerd idee.
Dit artikel werd oorspronkelijk geplaatst in KIJK’s zomernummer van 2020.
Tekst: Nick Kivits
Beeld (header): 123rf